Big Data is a common term thrown about in tech circles these days, almost every mid to large size company wants to use Big Data analysis to solve all their problems. Although proclamations of the omnipotent of Big Data analysis should be treated with some skepticism, however, there are use-cases where such a system is invaluable. This article covers the basics of setting up Apache Hadoop cluster, Hadoop is one of the most popular big data platforms out there and familiarity with it will give you a good overview of working with Big Data. In a subsequent article we will go through writing a simple Word-Count map-reduce job to run on the cluster. In future articles we will cover setting up multi-node clusters. In addition we will also focus on Hadoop tooling such as Apache Hive for data warehousing, Apache Flume and Apache Sqoop for data ingest and lastly Apache Oozie for workflow management.
Installing Docker
We will use the Docker platform for setting up the Hadoop cluster in this and subsequent articles. For those unfamiliar with docker it is a platform to applications in isolated containers similar to a virtual machine but without the overhead. We are using docker rather than natively installing Hadoop because it makes it much easier to repeatably get the same installation. The exact instructions are specific your operating system and are available in the documentation but we are going to run through the OSX instructions here.
- Download Boot2docker
- Run the installer, which will install VirtualBox and the Boot2Docker management tool.
- Run the Boot2Docker app in the Applications folder:
Running Dockerized Hadoop
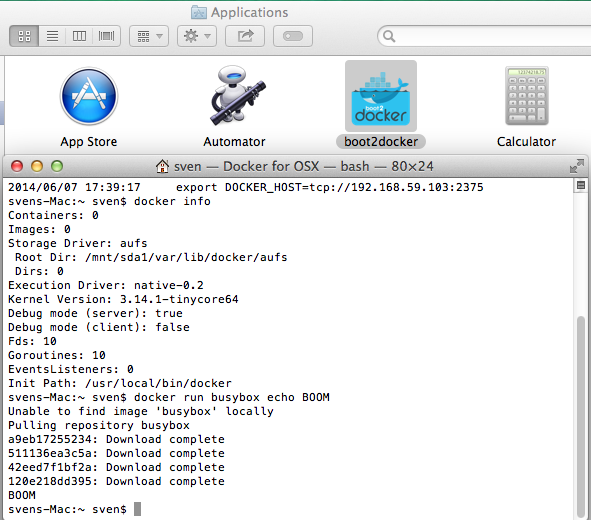
To run hadoop run the command shown below, in the boot2docker terminal window. This will download the docker image for Hadoop and run it, by default it runs in the single-node pseudo-cluster mode which is what we want anyway. For a description of available the parameters to docker take a look at the documentation. The parameters we have used are as follows:
- -i: Tells docker to run a container with an image.
- -t sequenceiq/hadoop-docker: Tells docker which image to use, i.e. sequenceiq/hadoop-docker. The source code for this image is available in github here.
- -p 50070:50070 Tells docker that the 50070 network port inside the container should be mapped to the 50070 port of the host machine.
- /etc/bootstrap.sh -bash are the commands passed to the container needed to run the hadoop inside the container.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
docker run -p 50070:50070 -i -t sequenceiq/hadoop-docker /etc/bootstrap.sh -bash
/
Starting sshd: [ OK ]
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-93e31c869d85.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-93e31c869d85.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-93e31c869d85.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn--resourcemanager-93e31c869d85.out
localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-93e31c869d85.out
bash-4.1#
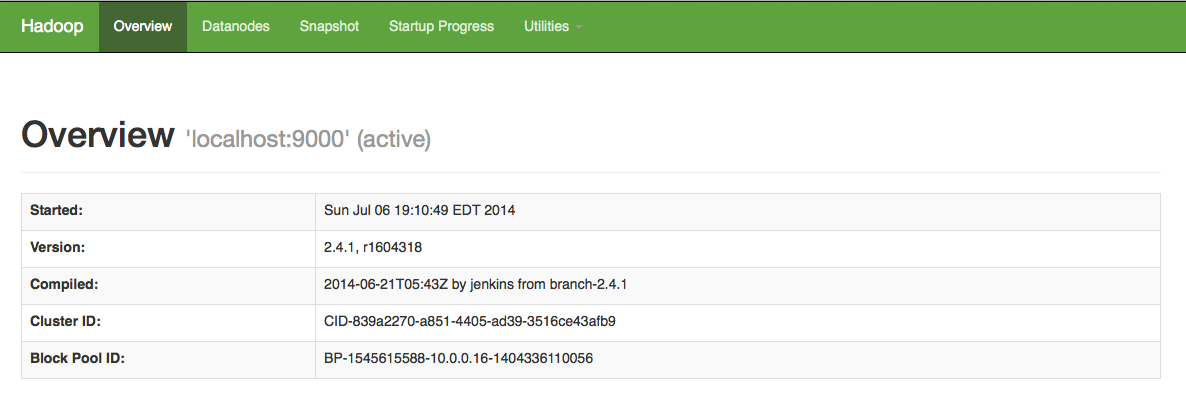
Once the command is run you will be inside the docker container which has Hadoop configured and installed. Now browse too http://192.168.59.103:50070 in your browser of choice and you should see the Hadoop configuration page shown below. That is all there is too it, next we move to Writing your first Hadoop Job.