I recently took part in a panel discussion discussing continuous delivery of micro-services hosted by ElectricCloud with Daniel Rolnick, Darko Fabijan and Anders Wallgren. The discussion is worth a listen if you have a spare hour however I would like to discuss some of the interesting points that came out of the discussion regarding the challenges inherent in micro-services deployments.
Team Overhead
Micro services architecture has a lot of benefits around the development process. It allows large teams to move rapidly semi-independent from each other. In addition it allows rapid prototyping and iteration on small feature sets. However, micro-services put a significant operational and tooling overhead on your development teams. Each of your services requires a deployment pipelines, a monitoring system, automated alerts, on-call rotations and so forth. All of this overhead is justified for large teams as the payoff from added productivity of feature work is worth the effort of creating these systems. However, in small teams if the same few people are responsible for all the services anyway replicating the pipelines for multiple project is wasted overhead. As Anders highlighted, you should write version 1.0 of your system as a monolith and then spin-off micro-services from the monolith as and when they make sense. This is will also allow for the emergent design around how the system breaks down into a service.
Operations Overhead
There is also an operational overhead to running so many services. In the monolith world if you push a bad version you roll the system back, if your are getting resource constrained you scale out horizontally. In the micro-services world the steps are the same however you need a lot more monitoring and automation to detect; Which of the tens of services needs to be rolled back? What is the impact of the rollback on other dependent services? If capacity needs to be added which services should it be added for? Will that just push the problem down stream to other services? If you have automated alerting (which you really should) then we need to ascribe alerts to service owners and then maintain on-call schedules for multiple services. In a small organization there will be a lot of overlap in the sets of people responsible for each service. This means we will have to coordinate the schedules for these services to make sure the same person is not on the hook for too many services and that people get some respite from on-call rotations. For these reasons as well as those mentioned in the previous section, its better to have a monolith and get all your operational ducks in a row before you start adding the overhead of multiple micro-services into the mix.
Distributed Debugging
With micro-services when things go wrong you can’t just log into a server and eye-ball the logs. The logs for a single user-session and in fact even a small process within the session will be spread over many different services. This was already true for monolithic scalable stateless servers but in the micro-services world not having centralized logging is a show-stopper. Furthermore, at large scale having separate monitoring systems (such as datadog, grahite) and separate log aggregation systems (such as ELK, loggly or Splunk) is not feasible. At this scale visualizing metrics and log data is a big-data problem that you are better of solving in one place.
Deployment Coordination and Version Management
Lastly, one of the big differences between monolithic and micro-services is that you are going from a dependency tree of services into a graph. For example a typical service stack in the monolithic model may consist of a web array, which calls a cache layer, database layer and maybe a few stand-alone services such as authentication etc. In the micro-services model you will have an interconnected graph or network of services each of which depends on several others.
It is very important to ensure that this graph remains a Directed Acyclic Graph (DAG) otherwise you will be in dependency hell and potentially have distributed stack overflow errors.
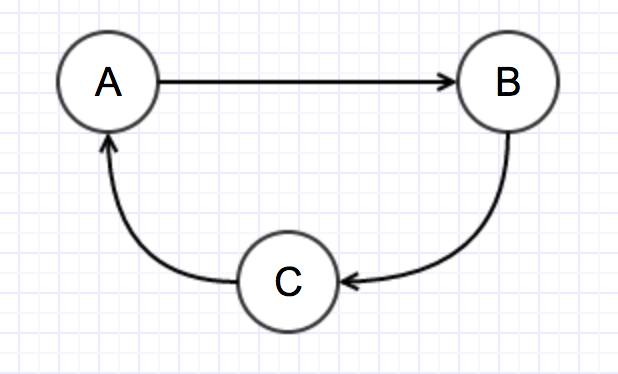
For example as shown in the example above, service A calls service B which calls service C which calls service A. If the first call to service A is the same as the second you will be in an infinite loop. If the first call is different from the second you may still be able to make progress but you can get into dependency cycles. For example an update to the API of service A will potentially require a change to service C. However, before Service C can be updated service A needs to be updated for the new API. Which do you do first? What happens to the traffic when one of the services is updated and the other is not?
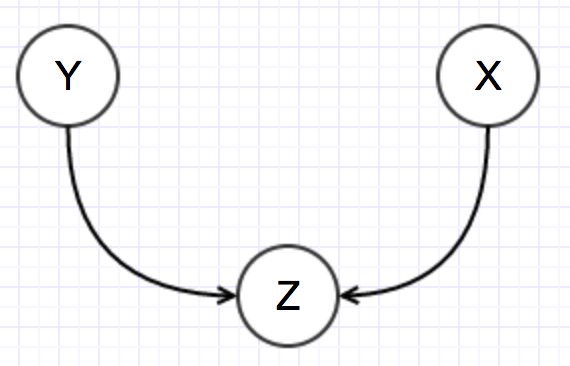
A similar issue arises when you you have two services depending on a third services, i.e. Service X and Service Y both call Service Z. What if service X depends on a different version of Z than Y. For these (and other) reasons we recommend that you always maintain backwards compatibility of all APIs or have very good mechanisms for detecting and responding to the issues highlighted above.
Guidelines
No one in the panel was comfortable enough with their micro-service system to propose anything like a guide for how to go about building such a system however, we did come up with some rules of thumb or general guidelines including the following.
Build/Use a Platform
We have hinted this earlier but with micro-services you will need to setup a lot of infrastructure, if you do this for each of your services the overhead be prohibitive. It is only possible to run micro-services deployments if you have automated all your infrastructure creation and management tasks. In other words, you must build or use a micro-services platform before you start writing micro-services. Kubernetees, Swarm, Mesos and their ilk will get you lot of the way there but you still need to unify your monitoring, debugging, continuous pipelines and service discovery mechanisms.
Everything must be code-defined
Following on from the previous point you cannot afford to have any part of your system be defined using human processes. Everything must be defined in code, testable and repeatable. For example, your server/VM setup should be orchestrated using docker-machine, puppet, ansible etc. Your continuous pipelines should be created using something like the Jenkins DSL Plugin. Your deployment should be defined in something like Docker compose. Using this setup you can easily replicate your setup for each new service and also push infrastructure updates and fixes to your entire set of services quickly.
Centralize Monitoring, Logging and Alerting
Before you write your first micro-service you need to have a central system to ingest, index and present your system metrics and logging events. Not only that but you need some form of anomaly detection and monitoring that is able to analyze events from each new service that gets added without manual intervention. While a monolithic service is like a beloved pet, you know all of its quirks and habits, micro-services are like cattle; you need all of them to be more or less identical, and managed as a generic herd rather than an individual.
Enforce backwards and forwards compatibility
You must use a design paradigm and tool set that ensures the API is always backwards and forwards compatible between services. At kik We use a system called GRPC which allows us to easily define services and their dependence using Protocol Buffers. Only using optional fields and coding for missing fields helps us ensure our services are resilient to version mismatch. Daniel mentioned that Yodle uses Pact JVM to help with testing compatibility at this layer. There are a host of testing and service definition frameworks to choose from but make sure your tools and dev process catches API breaking changes.
Micro-services as Networks
Lastly, we recommend you visualize a large micro-services deployment as a network. Monitoring and managing a large micro-services deployment is very similar to managing a network system. We need to make sure that requests(packets) do not infinitely loop in the services(routers). Maybe we can use the concept of TTLs to limit the number of hops. We need detect and respond to failures at edges, if a service deep down in the call hierarchy is down do we need to do all the calls to get to that service or can we shed load by preempting the request early (very similar BGP Route availability). We need to make sure that services are not overloaded by calls from other services, maybe we can use concepts from congestion control work on networks, Heka and Hystrix may be useful in this area.
Summary
Micro-services are a huge step forward in defining scalable, manageable and maintainable deployments and is a natural progression of the service oriented architecture. However, they are not a magic bullet to solve the fundamental problems of building and running distributed software at scale. A micro-services architecture does force you to be more conscientious about following best practices and automating workflows. The big take away from the discussion is that unless you are willing to divert a lot of time and resources from feature work into building and maintaining a service framework, its better avoid taking the plunge into the micro-services world. If however, you can invest the time to build a great service framework and workflow then you will come out of the transition as a more agile and productive organization.