This article is prompted by the recent AWS outage and articles and comments on sites such as techcrunch which assume that cloud based services are not reliable. There is no secret sauce for fault-tolerant services that Amazon or (any other cloud provider) can sprinkle on your service. Even if you were to manage your infrastructure yourself you would need to plan for and build redundancy to ensure a reliable service. In this article I will not describe best practices for service design which are described very well here. I will instead focus on building redundancy by putting your service behind an Elastic Load Balancer in multiple availability zones and then making multiple instances of these clusters in different regions.
Availability Zones
The first layer of redundancy is to run your service on several servers even if your service can be run out of one large instance. If any one of these servers fails your users will not even notice as their requests will just go to the alternates. In addition when launching instances make sure you spread your instances in as many availability zones as possible. Amazon’s infrastructure is such that the network connectivity, power and other connections for each zone are as independent as possible. Hence if a car drives into the data centre power source or is the data centre is struck by lightening only one of the availability zones is likely to be affected.
Elastic Load Balancer
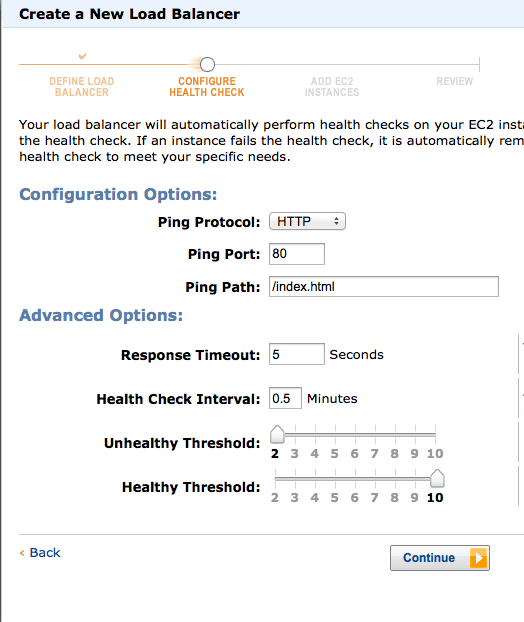
Now that you have all these servers how to you distribute requests across the servers. You need a http proxy to to relay requests to actual service servers in a randomized fashion. If you are on the EC2 cloud than you can just use the Elastic Load Balancing (ELB) service. You can create an ELB from the amazon console and register all your servers. In addition just randomly distributing requests the ELB can also check the health of all your servers and automatically stop sending requests to unhealthy servers. When creating the ELB you will asked to configure the health check as shown below. The options are fairly self-explanatory. For example the settings shown below will cause the ELB to poll each server every 30s by sending an Http request to /index.html and if there is non 200 Ok response or no response in 5s then the check is considered a failure. Two consecutive failures will take that server out of the list of servers. If the server starts responding and there are 10 consecutive ok checks then the server is added back to the list.
Multiple regions
Every so often problems are not limited to just one availability zone but instead a complete data centre is running with diminished or no service. To be robust to such outages you need to create instances in multiple regions. The benefit of this approach is that regions are geographically distributed and hence a single event is very unlikely to impact more than one region. To launch a node in multiple regions select a region from the drop down menu in the EC2 tab of amazon console. (See image below). You can then proceed to bringing up instances in this region. Note that nodes in different regions are completely disjoint so you will be billed for cross-region traffic. Also the latencies across regions will be higher. So as much as possible try to keep regions completely independent of each other.
DNS Round Robin
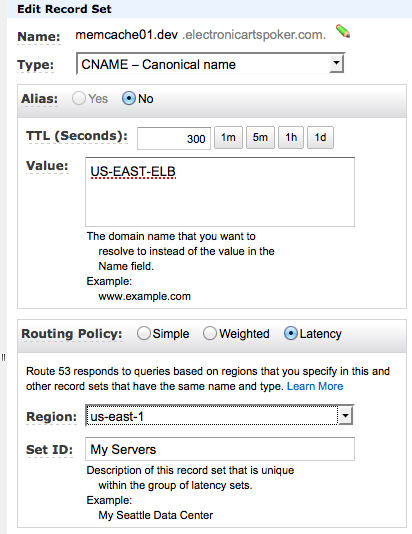
Unfortunately you cannot use one ELB across regions therefore to spread requests across regions you need to use DNS Round Robin. You can do this right out of the Route 53 tab in the amazon console. You do this by adding several A or CNAME type records for the same url. Amazon will then return one of the IPs (or hosts in case of CNAME) in response to a DNS query and will cycle through each of the records you add.
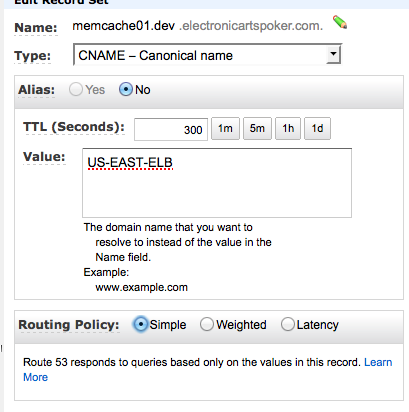
One thing to be aware of is that DNS results are cached on a node as well as intermediate name servers so if you want users to recover quickly after an outage you should select a smaller Time To Live (ttl) duration (Standard compliant caching will only cache as long as specified in ttl). However this is a trade-off because smaller ttls will mean more requests and slightly slower service as the client will resolve the address again before sending a request if it’s expired.
In addition to simple round robin amazon also allows routing based on a weighted round robin if you want to send most of your requests to one of the regions and more importantly amazon will also route based on service latency. This allows you to enter multiple DNS records (One for the ELB in each region) with the same ID. For each record you select the region that ELB resides in. Now amazon will automatically pick the region which is responding to requests quickest. If any region goes down or has diminished service your requests will automatically go to other regions.
Using these simple steps you can ensure the next time you reading about Ec2 outages taking down half the internet your service will not be one of the services that are effected.